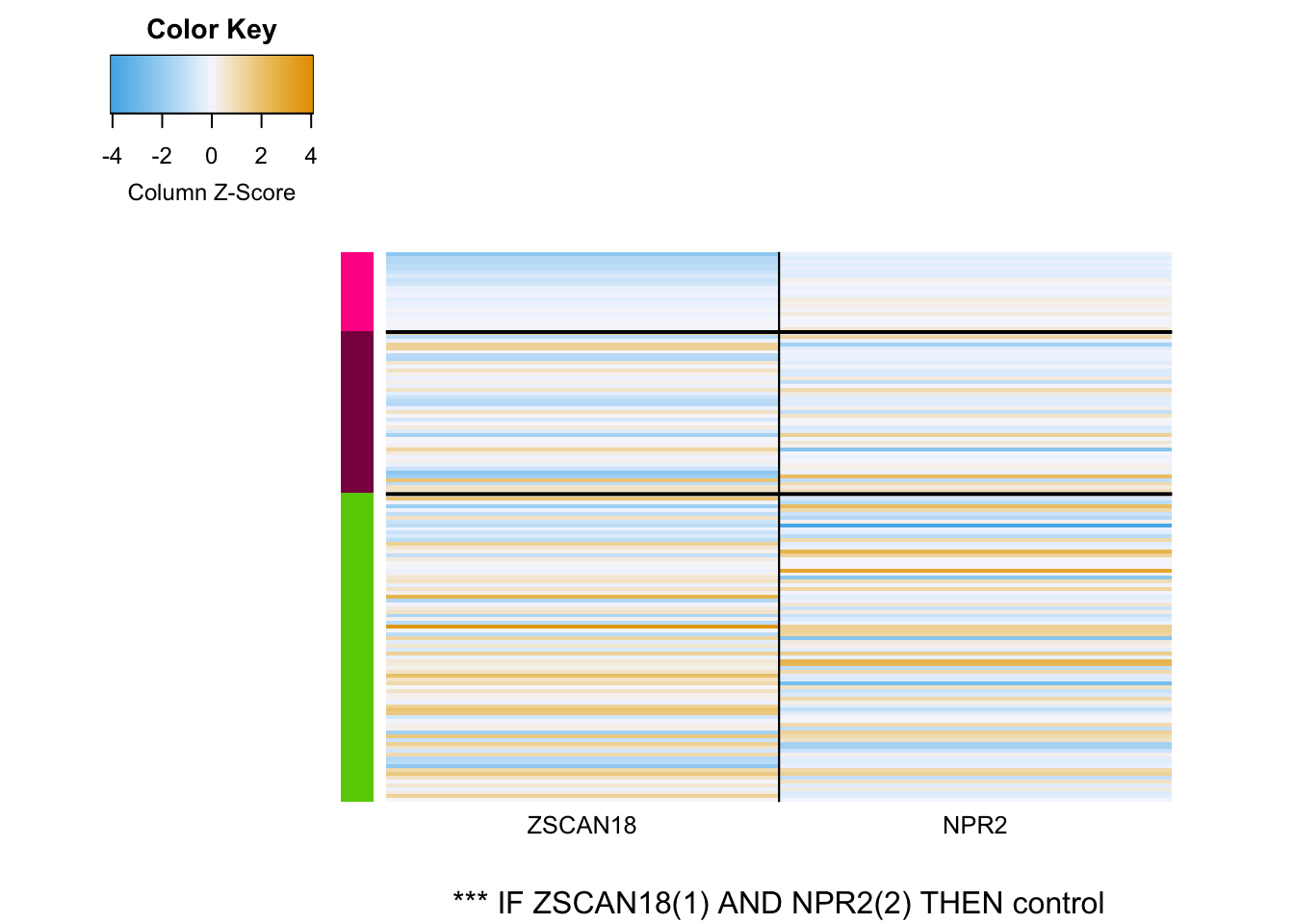
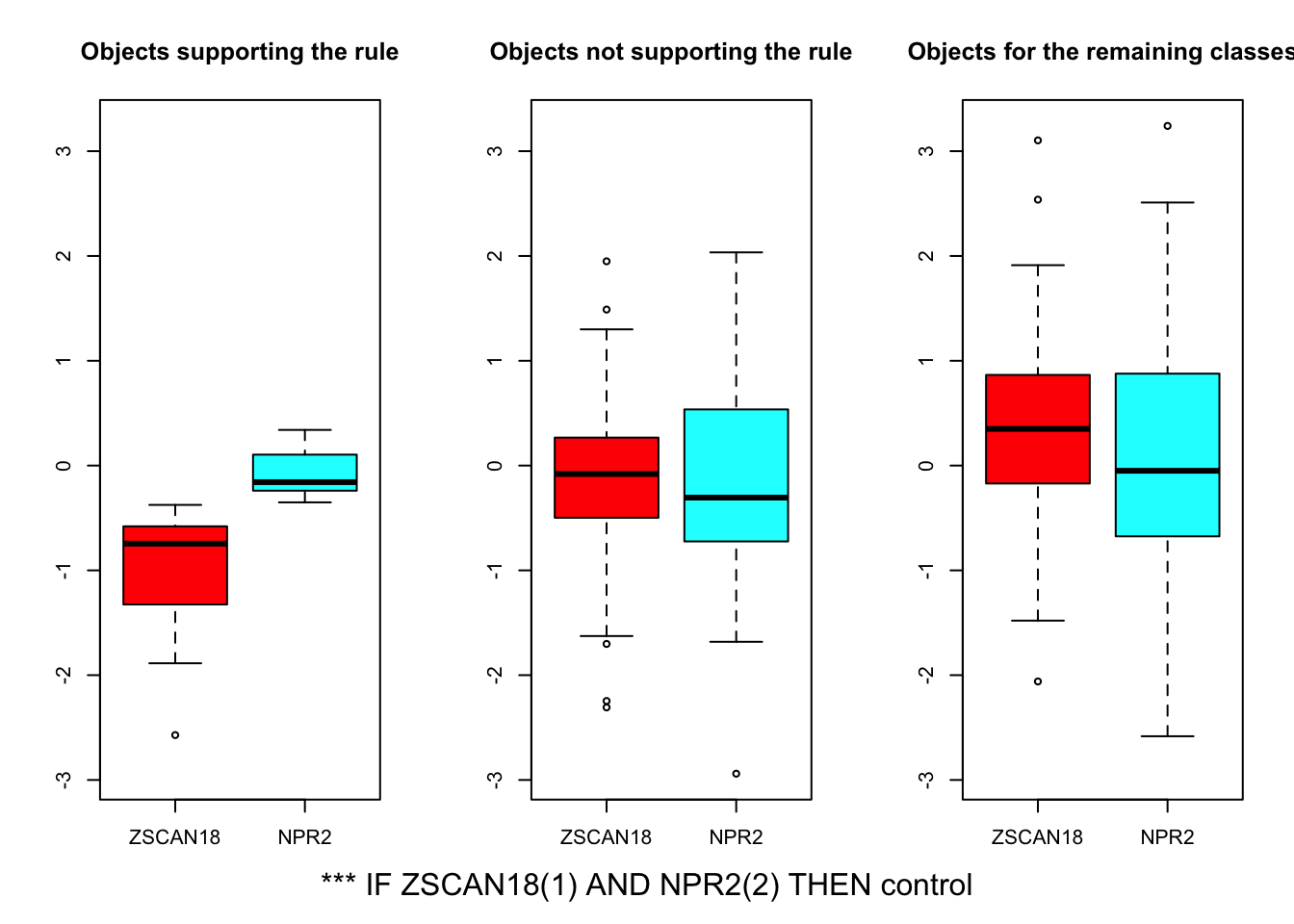
Main
The main output of the function contains a collection of rules in a table. The rule components and all statistics values are collected in separate columns. The individual values are comma separated.
dt <- synData(nFeatures=c(20,2,2,3,3), rf=c(0.2,0.2,0.3,0.5,0.5), rd=c(0.5,0.1,0.7,0.8,0.2), nObjects=100, nOutcome=2, unbalanced=F, seed=1)
out <- rosetta(dt)
out$main| features | levels | decision | support | accuracy | coverage | cuts | statistics | |
|---|---|---|---|---|---|---|---|---|
| rule_1 | F1,F2 | 1,2 | case | 43 | 0.97 | 0.174 | … | … |
| rule_2 | F2,F4,F5 | 2,1,3 | control | 40 | 0.95 | 0.142 | … | … |
| rule_3 | F2 | 3 | case | 36 | 0.89 | 0.097 | … | … |
| … | … | … | … | … | … | … | … | … |
| rule_n | F7,F1 | 3,1 | control | 10 | 0.64 | 0.014 | … | … |
- features - attribute names from a rule
- levels - discretization levels corresponding to a features
- decision - decision class for a rule
- accuracy - rule accuracy, for RHS(Righ Hand Support)
- support - the number of objects supporting the rule, RHS(Righ Hand Support) or LHS(Left Hand Support)
- coverage - rule coverage, RHS(Righ Hand Support) or LHS(Left Hand Support)
- cuts - information about cuts (thresholds) used for discretization. This will not exist if we use
discrete=Toption. - statistics - rule p-values, risk ratios and confidence intervals for a rule.